GMKtecのEVO X2という計算機(公式の販売ページ)が一部で話題になっています。
EVO X2の何が注目されているのか?
CPU に Ryzen AI Max+ 395を搭載し、64GBもしくは128GBのメモリを搭載している構成になっています。Ryzen AI Max+ 395は高性能なiGPU(Radeon 8060S)を搭載しています。iGPUなのでVRAMとしてホストのメモリを共有する形になります。つまりこのiGPUには大容量のVRAMを割り当てることが可能です。128GBモデルの場合最大96GBのVRAMを割り当てることが可能です。
このVRAMの容量が昨今流行しているLLMを動作させるためには重要です。生成AIではVRAMを使って計算を行うため、この容量で動作させることができるモデルが決まります。
現在、コンシューマ向けのGPUではトップクラスの性能を持つRTX 5090はVRAMは32GBです。自分が普段使っている計算機にはRTX 4070 SUPERを使っていてこちらは12GBです。RTX 4070 SUPERだとQwen3の14Bのモデルは動かせますが、30B以上のモデルは難しいです。30BのモデルではVRAMが足りず、ホストのメモリを利用する形で動作させることは可能ですが現実的な速度では利用できないです。
Ryzen AI Max+ 395を搭載している計算機だと、このVRAMが最大で96GBも利用できるということになります。これだけの容量があるとQwen3の30Bはもちろん、32B、235Bまで動かすことが可能です。計算能力自体はdGPUのものと比較すると遅くなってしまいますが、そもそも動かせないモデルがあるというのは厳しいです。
こういう経緯があってRyzen AI Max+ 395を搭載しているEVO X2が注目されています。
せっかくなのでEVO X2買ってみた
この話題のEVO X2を自分も購入してみて、Ubuntu上に生成AIで遊べる環境を構築してみました。特にハマりどころもなく便利に使えています。同様の環境を作りたい方もいるかなと思ったのでインストールの際の備忘録も兼ねてまとめておこうと言うのが今回の記事です。
インストールしたLinux Distribution
無難にUbuntu 24.04のデスクトップ版を入れてみました。
Ubuntu 25.04を試しに入れてみたところAMDのGPUドライバがUbuntu 24.04向けのパッケージしか配ってなくて面倒だったのでUbuntu 24.04を再度入れ直しました。
Arch Linuxを入れるか悩みましたがとりあえず事例も多そうなUbuntuにしてしばらく様子を見てみようかと考えています。
GPUドライバのインストール
AMDのドライバのページの手順に従ってインストールできます。romcもこの手順で導入できます。
sudo apt update
wget https://repo.radeon.com/amdgpu-install/6.4.1/ubuntu/noble/amdgpu-install_6.4.60401-1_all.deb
sudo apt install ./amdgpu-install_6.4.60401-1_all.deb
sudo amdgpu-install -y --usecase=graphics,rocm
sudo usermod -a -G render,video $LOGNAMEインストール後、再起動すればgpuドライバが読み込まれて利用可能になっているかと思います。
amd-smi コマンドを使うことでGPUの情報を取得できるようになっているかと思います。 amd-smi monitor 、amd-smi process あたりのコマンドを使えばVRAM使用量やどのプロセスがGPU使っているかなどを確認できます。
Swap領域を増やす
ここは必須ではないのですが ollama で巨大なモデルを読み込もうとするとswap領域が必要で、さらにUbuntu 24.04はデフォルトで8GBのswap領域を作りますがそれでは不足らしく失敗します。
なので事前にswap領域を増やしておきます。
sudo swapoff -a
sudo fallocate -l 32G /swapfile
sudo chmod 600 /swapfile
sudo mkswap /swapfile
sudo swaponあとは、 /etc/fstab にも設定しておきます
/swapfile none swap sw 0 0という内容を追加しておきます。
また標準で作られる swap.img に関する行は削除しておきます。
とりあえずベンチマーク
高性能なGPUということなので試してみます。モンハンワイルズのベンチマーク結果です。
SteamのProton環境でまず動くことに驚きましたが、設定高でこれだけ動けば十分でしょう。
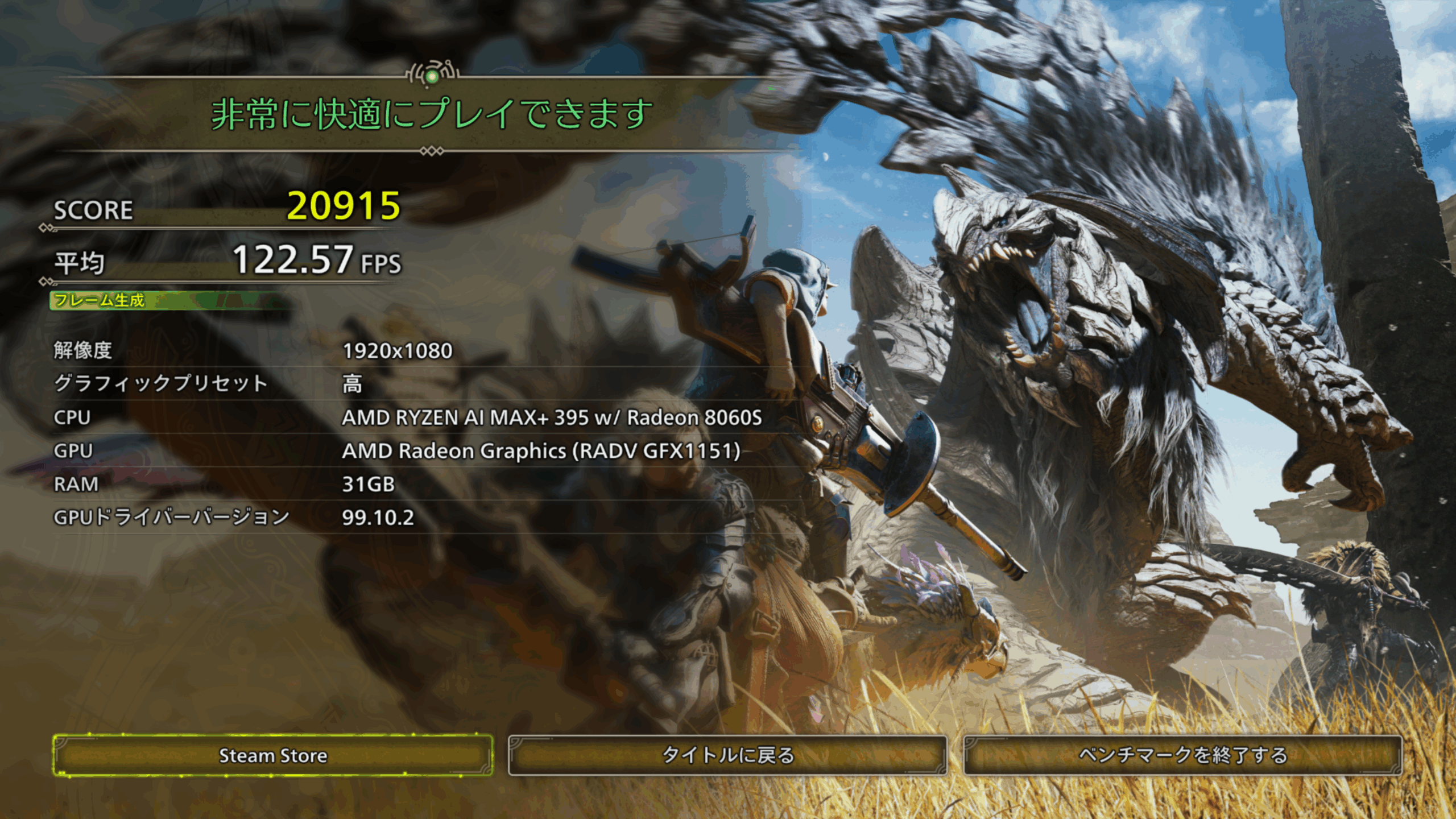
ちなみに、最近自分が一生懸命やっているアトリエシリーズはProtonで動かそうとすると新し目の作品(ライザ以降)は動くのですが、それより前のもの(黄昏、不思議シリーズ)は動画再生ができなかったり結構微妙です。EVO X2 + Ubuntuの環境だけで自分の生活が完結できなくて悲しいです。iGPUをGPU pass thruしてまでWindows VMを起動するか(できるのか?)というとしないと思うので、そのうちUSB-4にeGPUをつないでそれをVMから使わせるという方法でなんとかするかもしれません。
LM Studioを使ってみる
LM Studio がLLMを試す環境としては手頃です。AppImageを利用したLinux版もあります。こちらのページでLinux版を指定すればダウンロードできます。
これでバイナリを入手できます。AppImageはそのまま実行バイナリとしても実行できるのですが、インストールした直後の状態だと --no-sandbox のオプションをつけて実行しないと実行できません。
つまり以下のように実行する必要があります。
./LM-Studio-0.3.16-8-x64.AppImage --no-sandbox これで、LM Studioが起動できます。
起動したLM Studioの設定のRuntimeを見てみると vulkan llama.cpp が利用できるようになっているかと思います。これが有効になっていないとiGPUを使ってLLMを実行することができません。
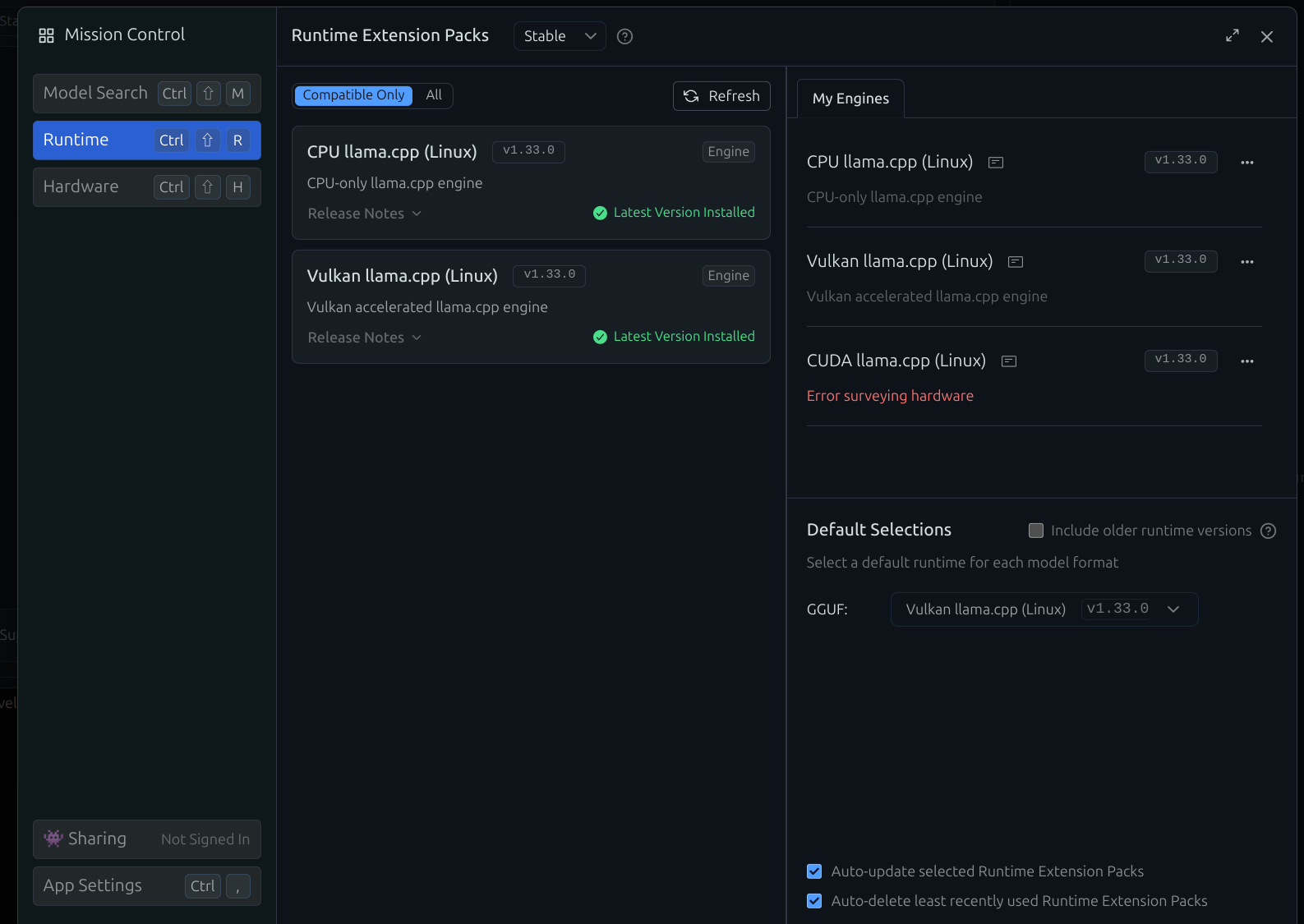
早速普段は実行ができなかったQwen3の235Bのモデルを実行してみます。
なお、235Bのモデルを実行するには色々ギリギリらしくモデルのロードのときにguardrails云々といって実行できないと思います。思い切ってOFFにして読み込ませて実施します。
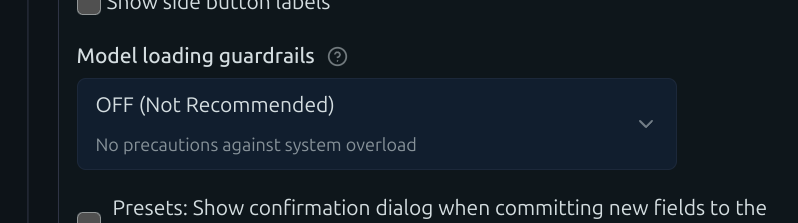
これでモデルをロードすると問題なく実行できました。素晴らしいですね。
15.06 tok/sec程度の速度で使えるようです。
ollamaのインストール
LM Studioは問題なく動いたので、次はollamaのインストールも行っていきます。cline、aider、open-webuiといったアプリから呼び出して使う想定です。公式のページからインストールのスクリプトを使ってインストールします。
curl -fsSL https://ollama.com/install.sh | shこのコマンドでインストールできます。
なお、このインストールした状態ではollamaに対して外部から接続できません。なので systemd の unitファイルを編集します。 /etc/systemd/system/ollama.service ファイルを以下のように編集します。
[Unit]
Description=Ollama Service
After=network-online.target
[Service]
ExecStart=/usr/local/bin/ollama serve
User=ollama
Group=ollama
Restart=always
RestartSec=3
Environment="PATH=/usr/local/texlive/bin:/home/sakura/.krew/bin:/home/sakura/bin:/home/sakura/.asdf/shims:/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin:/usr/games:/usr/local/games:/snap/bin:/snap/bin:/home/sakura/.local/bin:/home/sakura/.local-roswell/bin:/home/sakura/.local/roswell/bin:/home/sakura/Applications/go/bin:/home/sakura/.local/bin:/home/sakura/.local/roswell/bin:/home/sakura/.lib/node/bin:/usr/local/texlive/bin/" "OLLAMA_HOST=0.0.0.0:11434"
[Install]
WantedBy=default.targetEnvironmentの一番最後に "OLLAMA_HOST=0.0.0.0:11434"を追加しているのが変更点です。これで外部から接続できるようになります。設定反映させるために以下のコマンドを実行します。
sudo systemctl daemon-reload
sudo systemctl restart ollamaこれでollamaが外部から利用できるようになりました。
なお、ネイティブでインストールするのを避ける場合はdockerを利用することもできます。
その場合は以下のようなコマンドでコンテナを起動できます。
docker run -d --device /dev/kfd --device /dev/dri \
-v ollama:/root/.ollama -p 11434:11434 \
--name ollama ollama/ollama:rocmこれで、EVO X2でLLMを実行する環境は概ね整ったのではないでしょうか。
今後の予定とか
自分は普段シェルからollamaを呼ぶコマンドとかを使っています。
例えばこういうものです。他にも以下のようなアプリをこれからデプロイしたり、使おうと考えています。
- open-webui
- cline
- aider
- emacsのellama
kubernetes上にopen-webuiを構築してollamaを呼び出して利用できるようにしたりは既にできているのですが、記事が長くなりすぎるので今回はこの辺までで終わっておきます。